Smegenų vaizdavimas, mašininis mokymasis gali padėti numatyti psichinės ligos riziką
Tyrėjai sujungia smegenų vaizdavimo duomenis ir superkompiuterius, kad nustatytų neurovizualinių duomenų modelius, kurie gali padėti numatyti psichinių sutrikimų, tokių kaip depresija ar demencija, riziką.
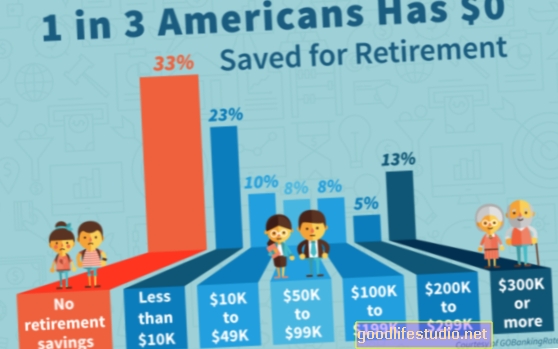
Kasmet depresija serga daugiau nei 15 milijonų suaugusiųjų amerikiečių, arba maždaug 6,7 proc. JAV gyventojų. Tai yra pagrindinė neįgalumo priežastis 15–44 metų asmenims.
Dr. Davidas Schnyeris, kognityvinis neuromokslininkas ir psichologijos profesorius Teksaso universitete Ostine, teigė, kad gebėjimas numatyti psichinių ligų riziką nėra paprastas dalykas.
Jis naudoja superkompiuterį mokydamas mašininio mokymosi algoritmo, kuris gali nustatyti šimtų pacientų bendrumą, naudojant magnetinio rezonanso tomografijos (MRT) smegenų nuskaitymus, genomikos duomenis ir kitus svarbius veiksnius, kad būtų galima tiksliai numatyti riziką tiems, kurie serga depresija ir nerimu. .
Mokslininkai ilgai tyrinėjo psichikos sutrikimus, tirdami smegenų funkcijos ir struktūros ryšį neurovizualiniuose vaizduose.
„Vienas šio darbo sunkumas yra tas, kad jis pirmiausia apibūdinamas. Gali atrodyti, kad smegenų tinklai skiriasi tarp dviejų grupių, tačiau tai nepasako apie tai, kokie modeliai iš tikrųjų numato, į kurią grupę pateksite “, - sakė Schnyeris.
„Mes ieškome diagnostinių priemonių, kurios galėtų nuspėti tokius rezultatus kaip pažeidžiamumas depresijai ar silpnaprotystė“.
2017 m. Schnyer, dirbdamas su įvairių universitetų mokslininkais, baigė analizės koncepciją patvirtinantį tyrimą, kuriame mašininio mokymosi metodu buvo klasifikuojami asmenys, turintys didelę depresiją, maždaug 75 procentų tikslumu.
Tarp tyrėjų buvo dr. Peteris Clasenas (Vašingtono universiteto medicinos mokykla), Christopheris Gonzalezas (Kalifornijos universitetas, San Diegas) ir Christopheris Beeversas (Teksaso universitetas, Ostinas).
Mašininis mokymasis yra informatikos pogrupis, apimantis algoritmų, kurie gali „mokytis“, sukurdami modelį iš duomenų pavyzdžių, konstravimą ir tada savarankiškai prognozuodami naujus duomenis, konstruoja.
Mokslininkai pateikė keletą mokymų pavyzdžių, kurių kiekvienas pažymėtas kaip priklausantis sveikiems asmenims arba tiems, kuriems diagnozuota depresija. Schnyeris ir jo komanda savo duomenyse pažymėjo prasmingas ypatybes, ir šie pavyzdžiai buvo naudojami mokant sistemą.
Tada kompiuteris nuskaitė duomenis, rado subtilius ryšius tarp skirtingų dalių ir sukūrė modelį, kuris priskiria naujus pavyzdžius vienai ar kitai kategorijai.
Tyrimo metu Schnyeris išanalizavo 52 gydymo ieškančių dalyvių, sergančių depresija, ir 45 sveikų kontrolinių dalyvių smegenų duomenis. Norėdami palyginti grupes, jie palygino depresijos dalyvių pogrupį su sveikais asmenimis pagal amžių ir lytį, todėl imties dydis buvo 50.
Dalyviai gavo difuzinio tensoriaus vizualizavimo (DTI) MRT tyrimus, kurie žymi vandens molekules, kad nustatytų, kiek tos molekulės laikui bėgant mikroskopiškai difuzinės smegenyse.
Tyrėjai palygino gautus dviejų grupių matavimus ir nustatė statistiškai reikšmingus skirtumus. Tada jie sumažino susijusius duomenis iki pogrupio, kuris buvo tinkamiausias klasifikavimui, ir atliko klasifikaciją ir numatymą naudodamiesi mašininio mokymosi metodu.
„Mes teikiame duomenis iš visų smegenų duomenų ar pogrupio ir prognozuojame ligų klasifikaciją ar bet kokią galimą elgesio priemonę, pavyzdžiui, neigiamos informacijos šališkumo matus“, - sako jis.
Tyrimas atskleidė, kad smegenų duomenys gali tiksliai klasifikuoti prislėgtus ar pažeidžiamus asmenis, palyginti su sveikais. Tai taip pat parodė, kad nuspėjama informacija yra paskirstoma smegenų tinkluose, o ne labai lokalizuota.
„Naudodamiesi DTI duomenimis, sužinojome ne tik apie tai, kad galime klasifikuoti depresiją patyrusius žmones, bet ir apie depresiją neturinčius žmones, mes taip pat sužinome apie tai, kaip depresija vaizduojama smegenyse“, - sakė psichologijos profesorius ir Psichikos sveikatos instituto direktorius Beeversas. Tyrimai Teksaso universitete, Ostine.
„Užuot bandę rasti sritį, kuri sutrikusi depresijos metu, sužinome, kad pokyčiai daugelyje tinklų prisideda prie depresijos klasifikavimo“.
Problemos mastas ir sudėtingumas reikalauja mašininio mokymosi požiūrio. Kiekvieną smegenį atstovauja apytiksliai 175 000 vokselių, o aptikti sudėtingo tokio didelio komponentų skaičiaus santykio, žiūrint į nuskaitymus, praktiškai neįmanoma.
Dėl šios priežasties komanda naudoja mašininį mokymąsi, kad automatizuotų atradimo procesą.
"Tai ateities banga", - sako Schnyeris.„Konferencijoje matome vis daugiau straipsnių ir pranešimų apie mašininio mokymosi taikymą sprendžiant sudėtingas neuromokslo problemas“.
Rezultatai yra daug žadantys, tačiau dar nėra pakankamai aiškūs, kad būtų galima juos naudoti kaip klinikinę metriką. Tačiau Schnyeris mano, kad sistema gali padaryti daug geriau, pridėjus daugiau duomenų, susijusių ne tik su MRT, bet ir su genomikos bei kitų klasifikatorių tyrimais.
„Vienas iš mašininio mokymosi pranašumų, palyginti su labiau tradiciniais požiūriais, yra tas, kad mašininis mokymasis turėtų padidinti tikimybę, kad tai, ką pastebime savo tyrime, bus pritaikyta naujiems ir nepriklausomiems duomenų rinkiniams. Tai turėtų būti apibendrinta pagal naujus duomenis “, - sakė Beeversas.
„Tai yra labai svarbus klausimas, kurį išbandome būsimose studijose.“
Šaltinis: Teksaso universitetas Ostine, Teksaso pažangiųjų skaičiavimo centras